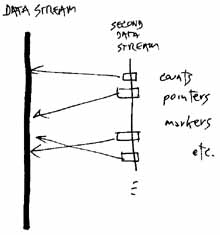
PARALLEL DATA STRUCTURES
Data should in general be parallel, with side-by-side indexing and
markup. Side-by-side data structures make sense. (See reference
1.)
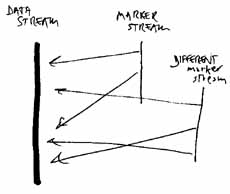
Examples of parallel data in popular software
Some people have seen the advantages of parallel data structures. One nice example is in the popular Eudora e-mail reader. The PC version of this program maintains the original Unix file structure of concatenated emails, but then marks their beginnings (and other information) in a parallel stream, the .toc file (table of contents). This is a nice example where the addition of a second parallel data stream allowed the first to be untouched.
A better-known, but less successful, example is the distinction in Macintosh
files between "data fork" and "resource fork". Unfortunately this
distinction has ceased to have any coherent fixed meaning, and whatever
it was originally intended to clarify has long since been muddied.
Deeper uses: The Xanadu®
software family
The Xanadu family of data structures has always (at least since 1970)
been designed around parallelism between contents and markup streams.
(We expect to publish the original design papers hereabouts shortly.)